
こんにちは、ひっぴです。
Pythonを使用してWebサイトをスクレイピングしていた際、以下を持つ表に苦戦しました。
- rowspanによる結合
- <tr>タグで囲まず<td>タグを並べている行
BeautifulSoupでタグを1つずつ処理することで対処したので、その方法とコード例を共有します。
対処した表とスクレイピング結果
今回スクレイピングしたのは以下のような表です。
※キャプチャは表の一部です。

一番左の列が、rowspanで2行分結合されています。
HTMLソースを見てみると、以下のような形でした。
<tr>
<td rowspan="2">2016年3月</td>
<td>予想</td>
<td>52.50</td>
...
</tr>
<td>実績</td>
<td>52.50</td>
<td>...</td>実績の行は<tr>タグで囲まれておらず、<td>タグのみが並んでいます。
「rowspanで結合されたセルの続き」として、タグ構造が崩れています。
この表を以下のようにデータ化することがゴールです。
<tr>タグがない行も漏らさず扱い、またrowspanで結合されている列を補います。

以前もこのような表を見かけた記憶があります。
こうした構造は意外とよくあるんですね。
当初の対応
trタグでfind
このような構造だと気づく前に、いつも通りfind_all(‘tr’)をしました。
当然、返却されるリストには抜けている行があります。
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table', class_='cs')
rows = table.find_all('tr')pandas.read_html()
続いて、read_html()を試しました。
スクレイピングではまず試したくなる便利関数です。
import pandas as pd
tables = pd.read_html("https://example.com/page.html")しかし今回の構造では、行数や列数がズレてしまい、正しいDataFrameが出力されませんでした。
解決方針:BeautifulSoupで丁寧に処理する
rowspanを考慮し、かつHTMLの構造崩れにも対応するには、タグをひとつひとつ追う実装が必要です。
以下のように処理をしました。
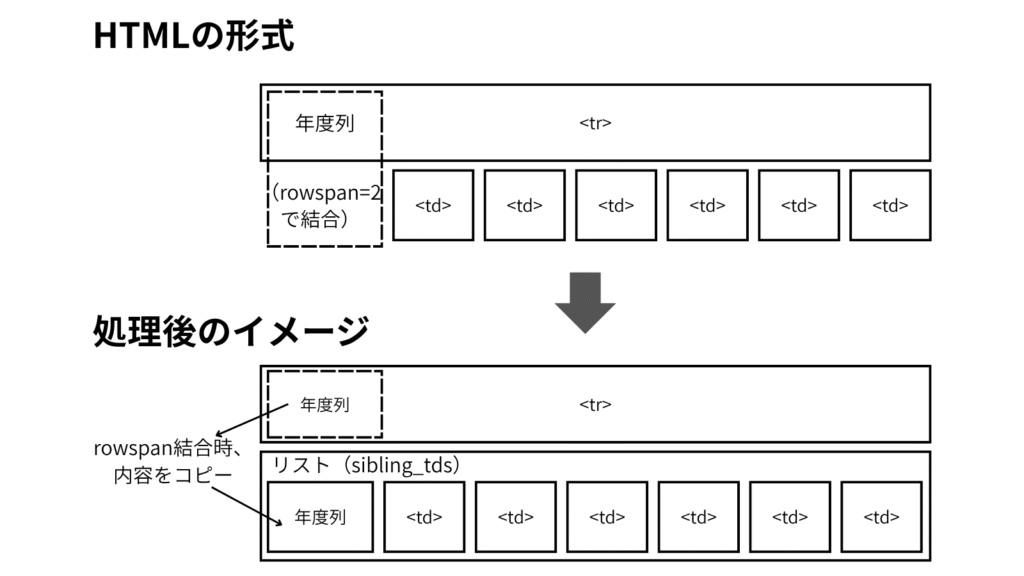
rowspanで結合されたセル(左端の年度列)がある場合、内容をコピーしておきます。
直後に年度列のない行が出現した場合、コピーした内容を補います。
また、<tr>タグ無しに<td>タグが出現した場合、リスト(図のsibling_tds)に詰めていきます。
このような行が複数行連続である箇所もあったため、<td>タグの個数を数え、適宜次のsibling_tdsに詰めるようにしています。
実際に使ったコード(抜粋)
以下は、私が使ったコードの該当箇所です。
# データの抽出
rows = []
sibling_tds = []
current_year = None
for tag in tbody.contents:
if not isinstance(tag, Tag):
continue
if tag.name == "tr":
# 直前に壊れた行(<td>だけ)を処理
if sibling_tds != []:
row = [current_year] + sibling_tds
rows.append(row)
sibling_tds = []
cells = tag.find_all("td")
# 年度セルの取得(rowspanあり)
if cells and cells[0].has_attr("rowspan"):
current_year = cells[0].get_text(strip=True)
# 年度補完(セル数が足りないとき)
row = [td.get_text(strip=True) for td in cells]
if len(row) < len(headers):
row = [current_year] + row
rows.append(row)
elif tag.name == "td":
# <tr>なしで<td>だけのケース(HTML構造が壊れている)
sibling_tds.append(tag.get_text(strip=True))
if len(sibling_tds) == len(headers) - 1:
row = [current_year] + sibling_tds
rows.append(row)
sibling_tds = []
# DataFrame 化
df = pd.DataFrame(rows, columns=headers)
変数名などを一部補足します。
for tag in tbody.contents:
がタグを取り出していくループ。<tr>、<td>を順番に処理rowspanを検出した場合- 内容を
current_year変数に記憶 - 以降の行で列数が不足している場合、
current_yearを補完
- 内容を
まとめ
表のスクレイピングにて、<tr>タグで囲まずに<td>タグのみが並んでいる行を処理しました。
「rowspanで結合されたセルの続き」として、タグ構造が崩れていたものです。
このような表は、BeautifulSoupを用いてタグを1個ずつ処理していくことで解決できます。


コメント